When your LLM pipeline silently returns zero
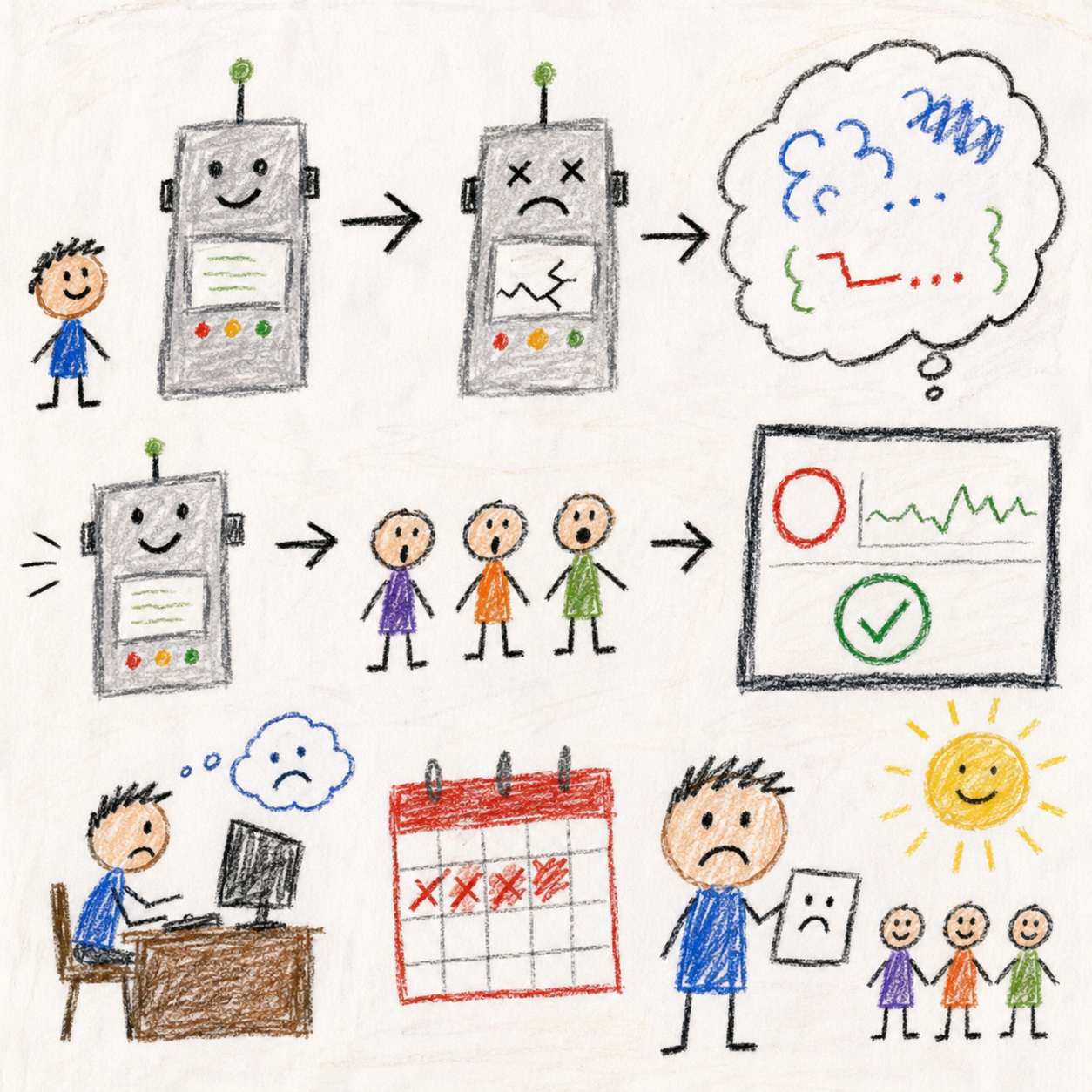
One Sunday morning the daily scan ran for a user of Loud Camel, a tool that helps academics promote their research and get cited. It came back clean: a couple dozen items scored, zero relevant, zero results delivered. That looked like the system telling me there were no good matches this week. It was the system screaming, with nothing logged.
The silent-but-deadly failure mode
Pardon the analogy. Silent failures in LLM pipelines work like the worst farts in an elevator: nothing audible, nothing on the surface, then you notice the room has emptied. The LLM call returned. The parser returned a Python dict. Every type check passed. The number returned was zero, and zero looked like the truth.
What actually went wrong
The model hit its max_tokens cap and the response was truncated mid-string. No closing brace, no closing fence. The JSON parser had a clever repair fallback: it scanned for key-value pairs regardless of nesting depth and reassembled them into a flat dict. The repair returned an object that was technically dict-shaped but contained the wrong keys, all from the truncated inner level of the structure. The consumer iterated, found nothing it recognized, defaulted every item to a score of zero. The dashboard showed zero relevant, the user got an empty scan, and the cost line read like everything was normal.
Two days later the same shape showed up in a different LLM call site. The model output truncated at a different limit, the parser returned a dict-shaped object with the wrong keys, the consumer produced zero results. The day after, a third call site failed the same way. Three places. One bug class. No alarms.
How to make a silent failure loud
Two cheap defenses, neither of which I had on Sunday morning.
First, the parser cannot be allowed to lie about shape. A truncated array should return None or the complete prefix, never an object. A truncated nested object should return only the outer-level keys that were complete, never the inner ones hoisted up. The fix is unit tests at the parser boundary that assert this shape contract. Zero LLM cost. Deterministic.
Second, the consumer must validate the shape before defaulting to zero. If the function expects a dict keyed by request IDs, it should check that the returned keys are request IDs and warn loudly if they are not. A single line that reads ‘scored 0 of N items, response shape unexpected’ would have turned a four-day silent outage into a four-minute fix.
Why this is the bug class to invest in
LLM call sites multiply faster than you can audit them. Every prompt change, every model change, every batch size change opens a new path to the same failure. Patching each call site after it bleeds is stop-gap engineering. The structural defense is to make the parser refuse to lie and the consumer refuse to be silent. Both run in tests, in milliseconds, with no token cost. Both would have caught all three of my outages before any user saw a zero.
Silent but deadly is funny once. It is not funny when a real user is waiting on an empty scan for a week.