Almost half a year ago, I decided to create an online data visualization course. After investing hundreds of hours, I managed to release the first lecture and record another one. However, I decided not to publish new lectures and to remove the existing one from the net. Why? The short answer is a huge cost-to-benefit ratio. For a longer answer, you will have to keep reading this post.
Why creating a course?
It’s not that there are no good courses. There are. However, most of them are tightly coupled with one tool or another. Moreover, many of the courses I have reviewed online are act as an advanced tutorial of a certain plotting tool. The course that I wanted to create was supposed to be tool-neutral, full of theoretical knowledge and bits of practical advice. Another decision that I made was not to write a set of text files (online book, set of Jupyter notebooks, whatever) but to create a course in which the majority of the knowledge is brought to the audience by the means of frontal video lectures. I assumed that this kind of format will be the easiest for the audience to consume.
What went wrong?
So, what went wrong? First of all, you should remember that I work full time at Automattic, which means that every side project is a … side project, that I have to do during my free time. I realized that since the very beginning. However, since I already teach data visualization in different institutions in Israel, I already have a well-formed syllabus with accompanying slide decks full of examples. I assumed that it will take me not more than one hour to prepare every online lecture.
[caption id=”attachment_630” align=”alignright” width=”225”]
Green room. All my friends were very impressed to see it[/caption]
So, instead of verifying this assumption, I started solving the technical problems, such as buying a nice microphone (which turned out to be a crap), tripods, building a green room in my home office, etc. Once I was satisfied with my technical setup, I decided to record a promo video. Here, I faced a big problem. You see, talking to people and to the camera are completely different things. I feel pretty comfortable talking to people but when I face the camera, I almost freeze. Also, in person-to-person communication, we are somewhat tolerant to small studdering and longish pauses. However, when watching recorded video clips, we expect television quality narration. It turns out that achieving this kind of narration is very hard. Add the fact that English is my third language, and you get a huge time drain. To be able to record a two-minute promo video, I had to write the entire script, rehearse it for a dozen of times, and record it in front of a teleprompter. The filming session alone took around half an hour, as I had to repeat almost every line, time after time.
[caption id=”attachment_648” align=”alignright” width=”300”]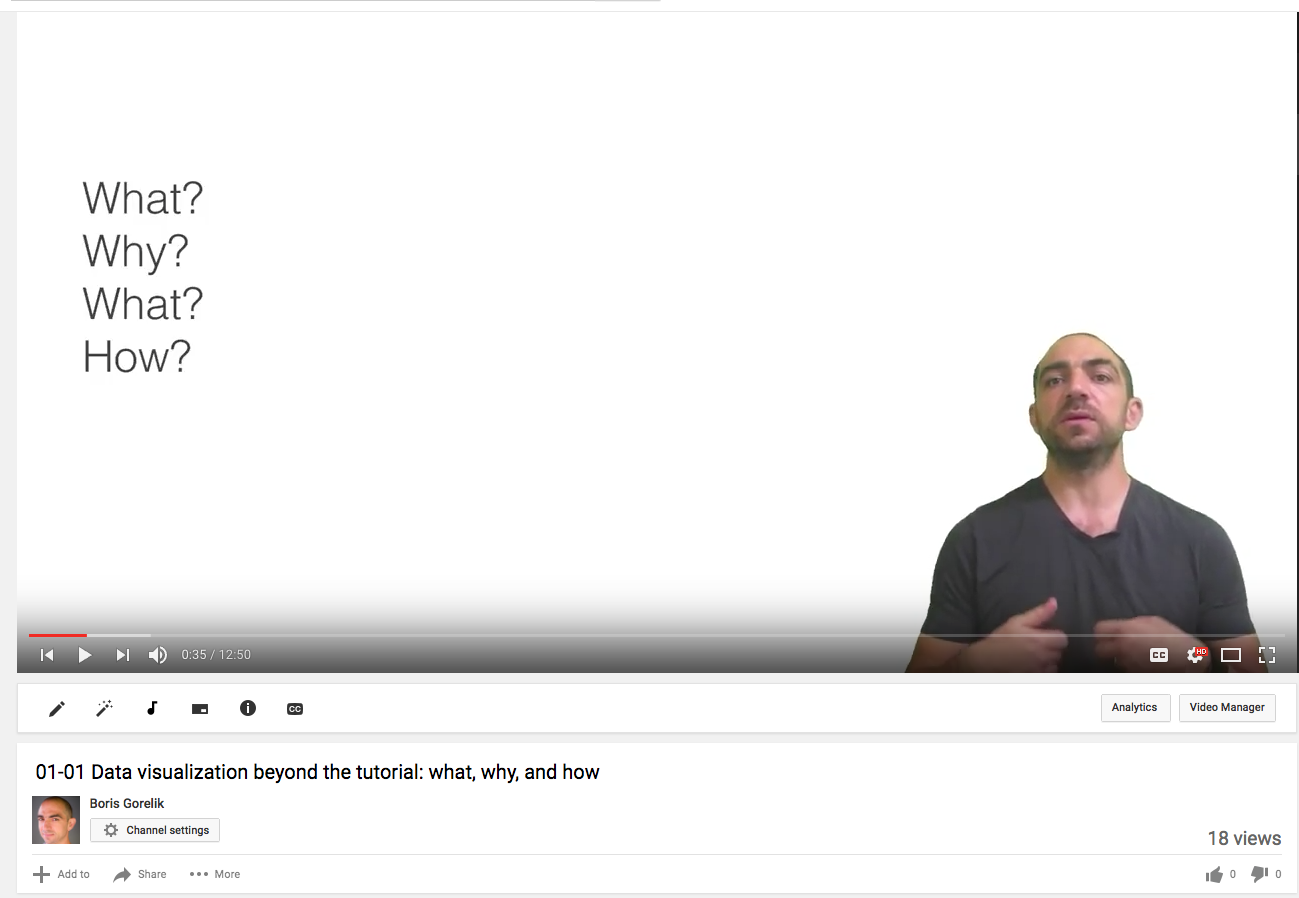
18 views.[/caption]
Preparing slide decks for the lectures wasn’t an easy task either. Despite the fact that I had pretty good slide decks, I realized that they are good for an in-class lecture, where I can point to the screen, go back and forth within a presentation, open external URL’s etc. Once I had my slide decks ready, I faced the narration problem once again. So, I had to write the entire lesson’s script, edit it, rehearse for several days, and shoot. At this time, I became frustrated. I might have been more motivated had my first video received some real traffic. However, with 18 (that’s eighteen) views, most of which lasted not more than a minute or two, I hardly felt a YouTube super star. I know that it’s impossible to get a real traction in such a short period, without massive promotion. However, after I completed shooting the second lecture, I realized that I will not be able to do it much longer. Not without quitting my day job. So, I decided to quit.
What now?
Since I already have pretty good texts for the first two lectures, I might be able to convert them to posts in this blog. I also have material for some before-and-after videos that I planned to have as a part of this course. I will make convert them to posts, too, similar to this post on the data.blog.
Was it worth it?
It certainly was! During the preparations, I learned a lot. I learned new things about data visualization. I took a glimpse into the world of video production. I had a chance to restructure several of my presentations.
Featured image for this post by Nicolas Nova under the CC-by license.