Recently, I stumbled upon a report called “Understanding Today’s Chief Data Scientist” published by an HR company called Heidrick & Struggles. This document tries to draw a profile of the modern chief data scientist in today’s Big Data Era. This document contains the ugliest pieces of data visualization I have seen in my life. I can’t think of a more insulting graphical treatment of data. Publishing graph like these ones in a document that tries to discuss careers in data science is like writing a profile of a Pope candidate while accompanying it with pornographic pictures.
Before explaining my harsh attitude, let’s first ask an important question.
What is the purpose of graphs in a report?
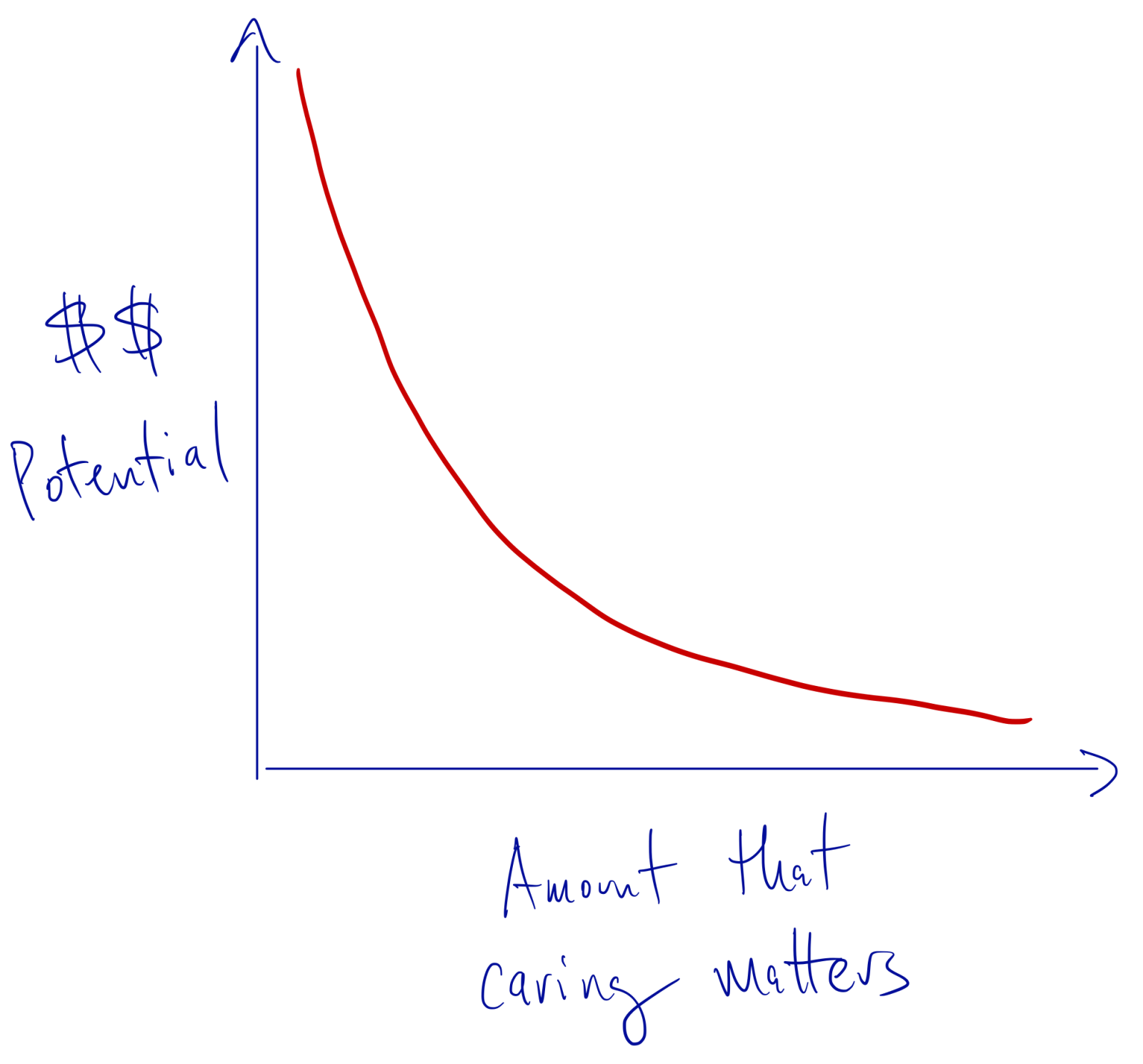
There are only two valid reasons to include graphs in a report. The first reason is to provide a meaningful glimpse into the document. Before a person decided whether he or she wants to read a long document, they want to know what is it about, what were the methods used, and what the results are. The best way to engage the potential reader to provide them with a set of relevant graphs (a good abstract or introduction paragraph help too). The second reason to include graphs in a document is to provide details that cannot be effectively communicating by text-only means.
That’s it! Only two reasons. Sometimes, we might add an illustration or two, to decorate a long piece of text. Adding illustrations might be a valid decision provided that they do not compete with the data and it is obvious to any reader that an illustration is an illustration.
Let the horror begin!
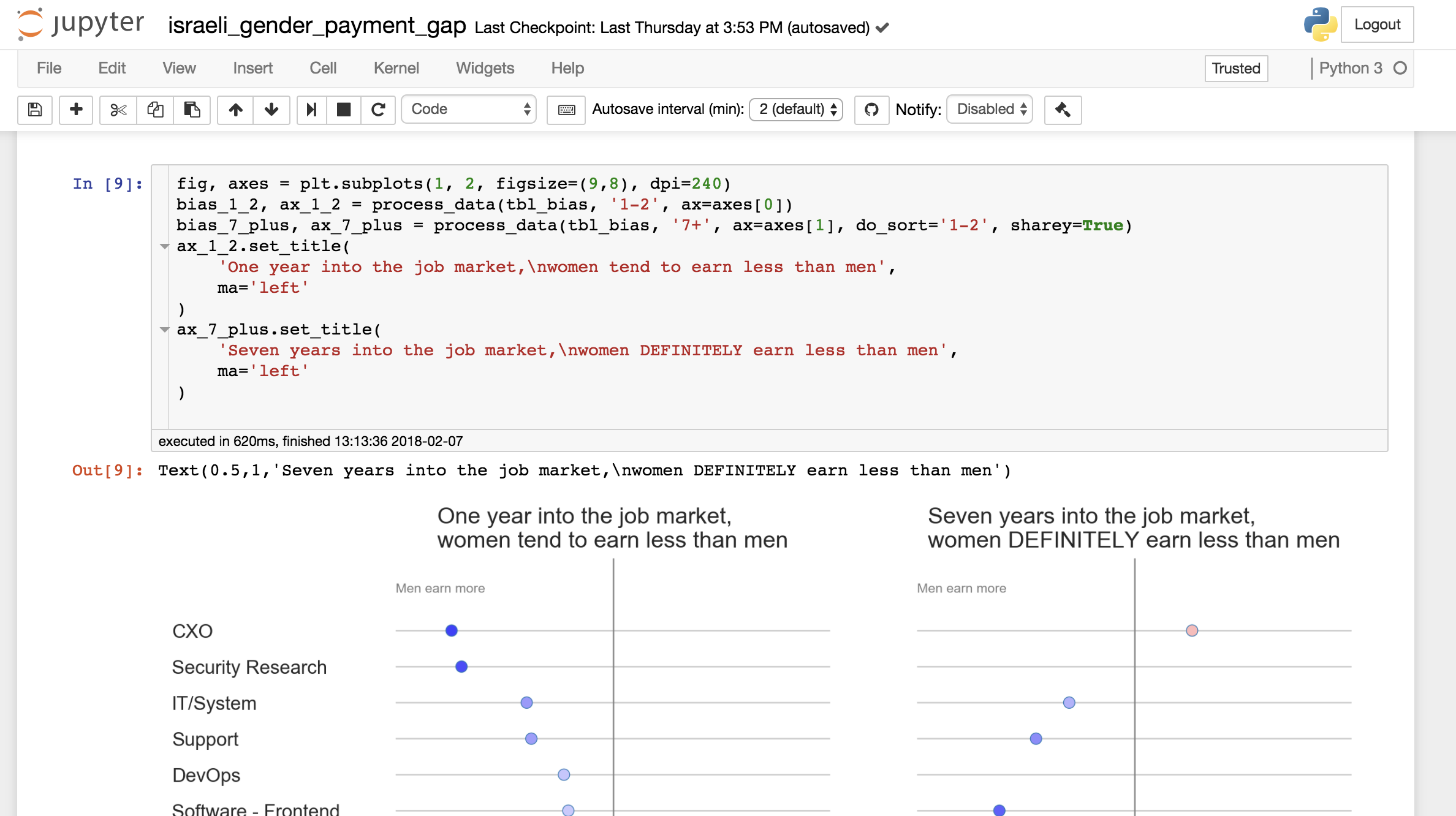
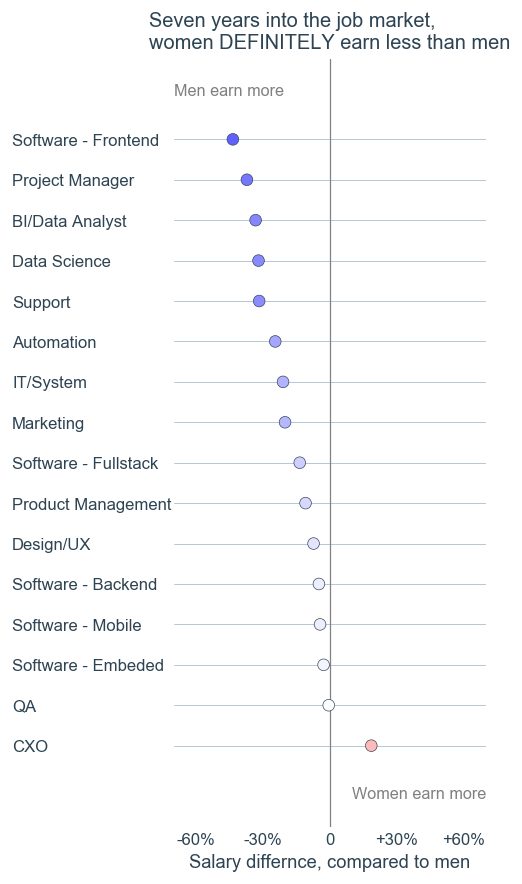
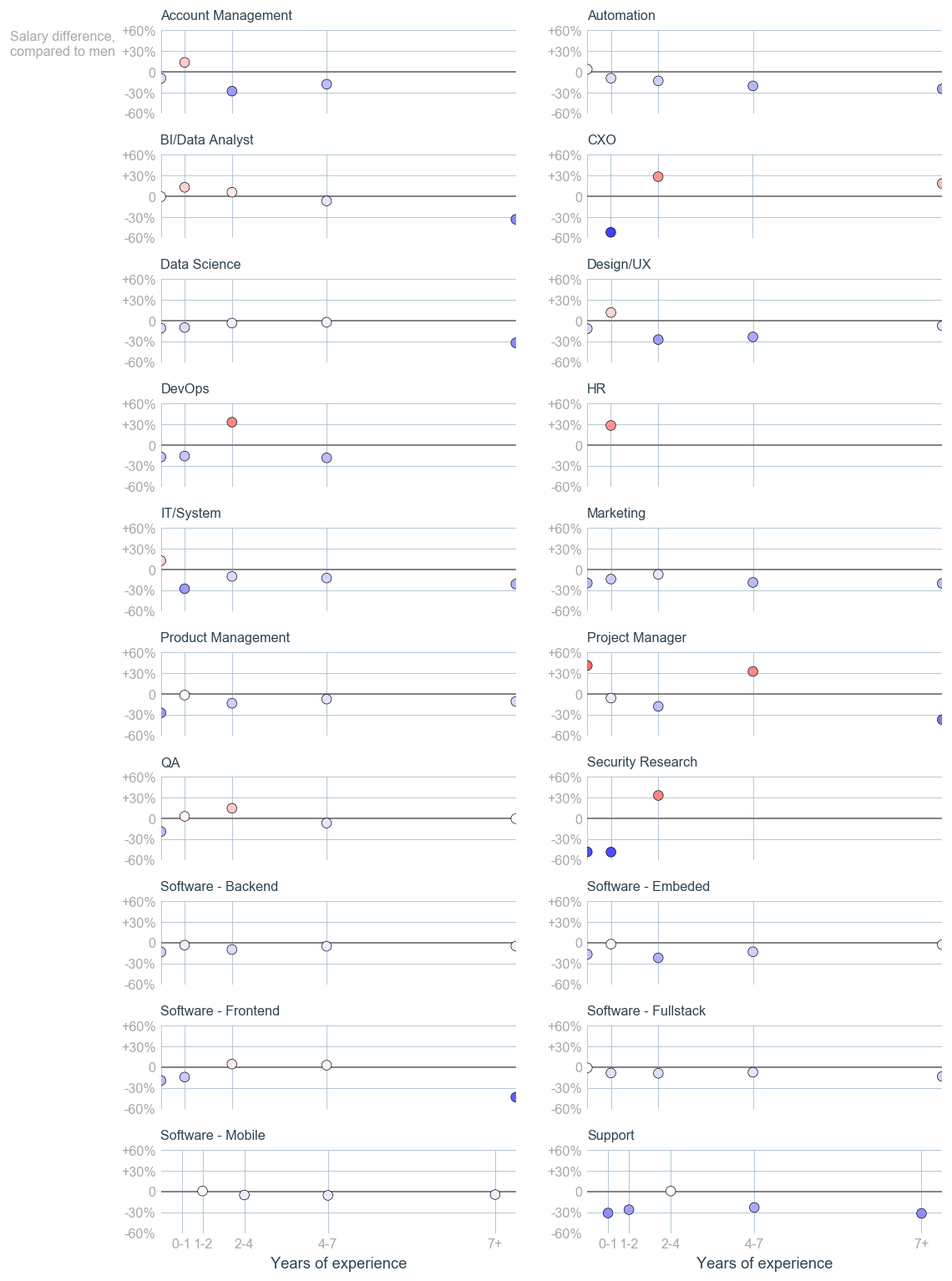
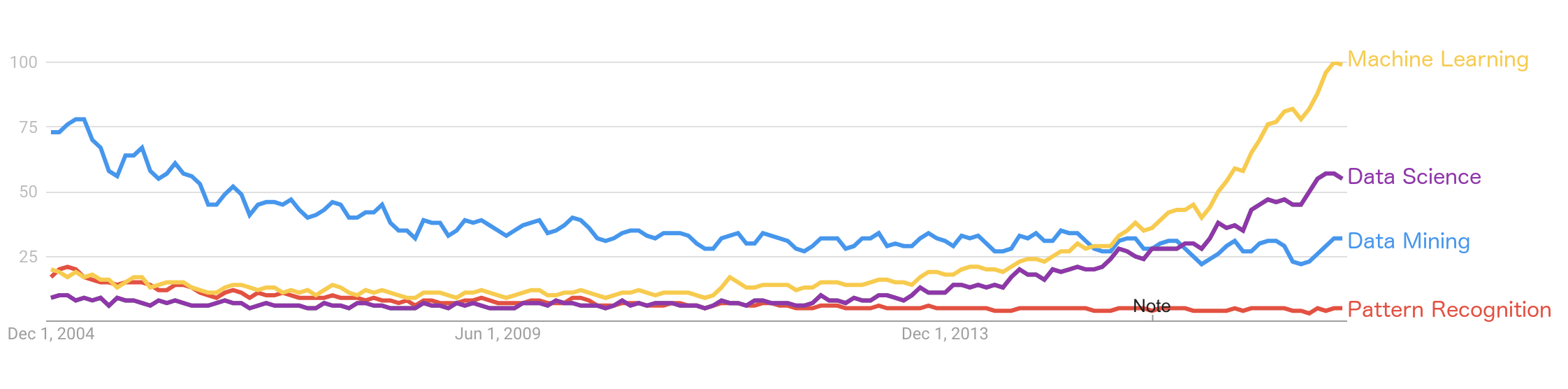
The first graph in the H&S report stroke me with its absurdness.
At first glance, it looks like an overly-artistic doughnut chart. Then, you want to understand what you are looking at. “OK”, you say to yourself, “there were 100 employees who belonged to five categories. But what are those categories? Can someone tell me? Please? Maybe the report references this figure with more explanations? Nope. Nothing. This is just a doughnut chart without a caption or a title. Without a meaning.
I continued reading.
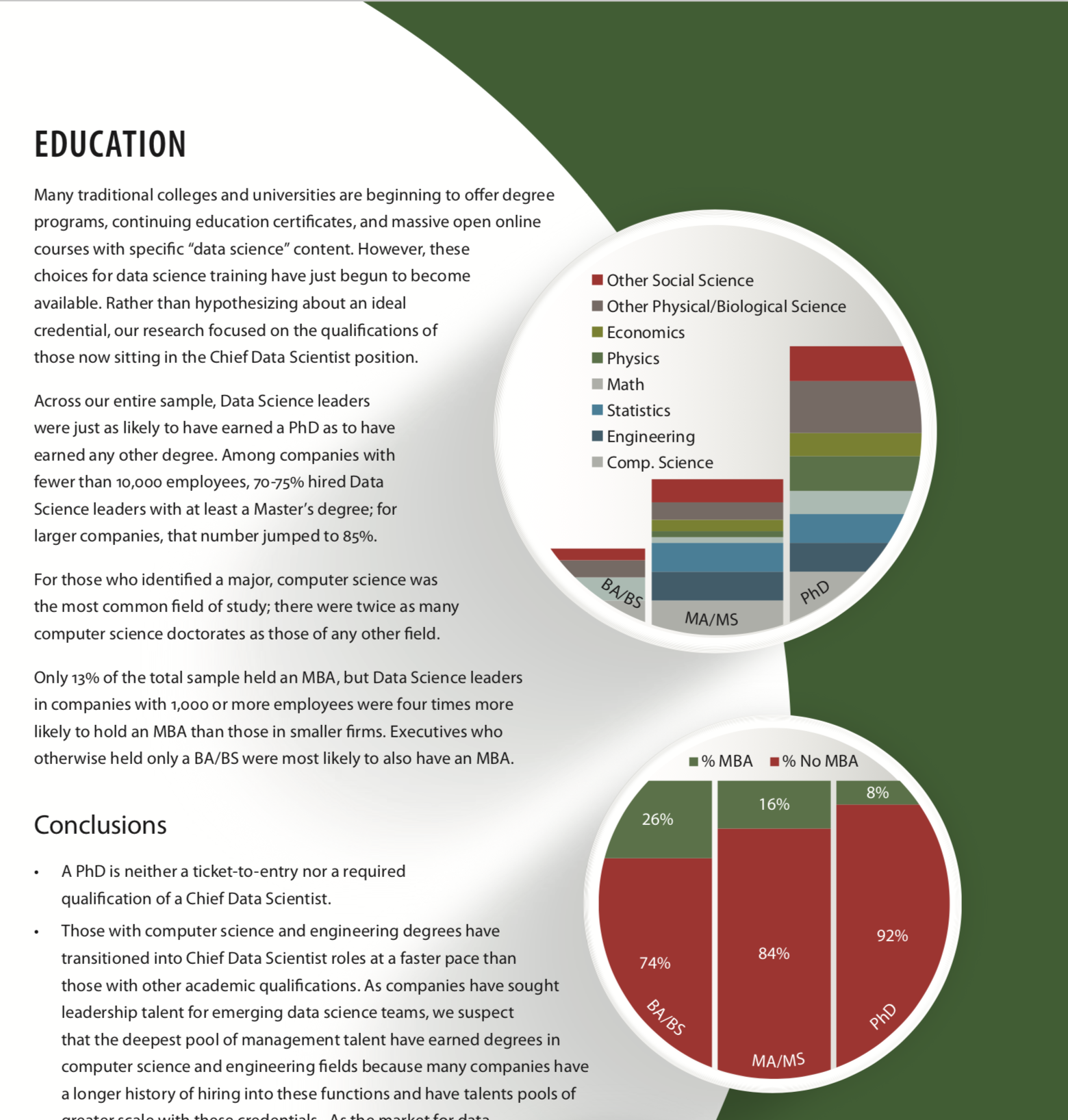
OK, so the H&S geniuses decided to hide the origin or their bar charts. Had they been students in a dataviz course I teach, I would have given them a zero. Ooookeeyy, it’s not a college assignment, as long as we can reconstruct the meaning from the numbers and the labels, we are good, right? I tried to do just that and failed. I tried to use the numbers in the text to help me filling the missing information and failed. All in all, these two graphs are a meaningless graphical junk, exactly like the first one.
The fourth graph gave me some hope.
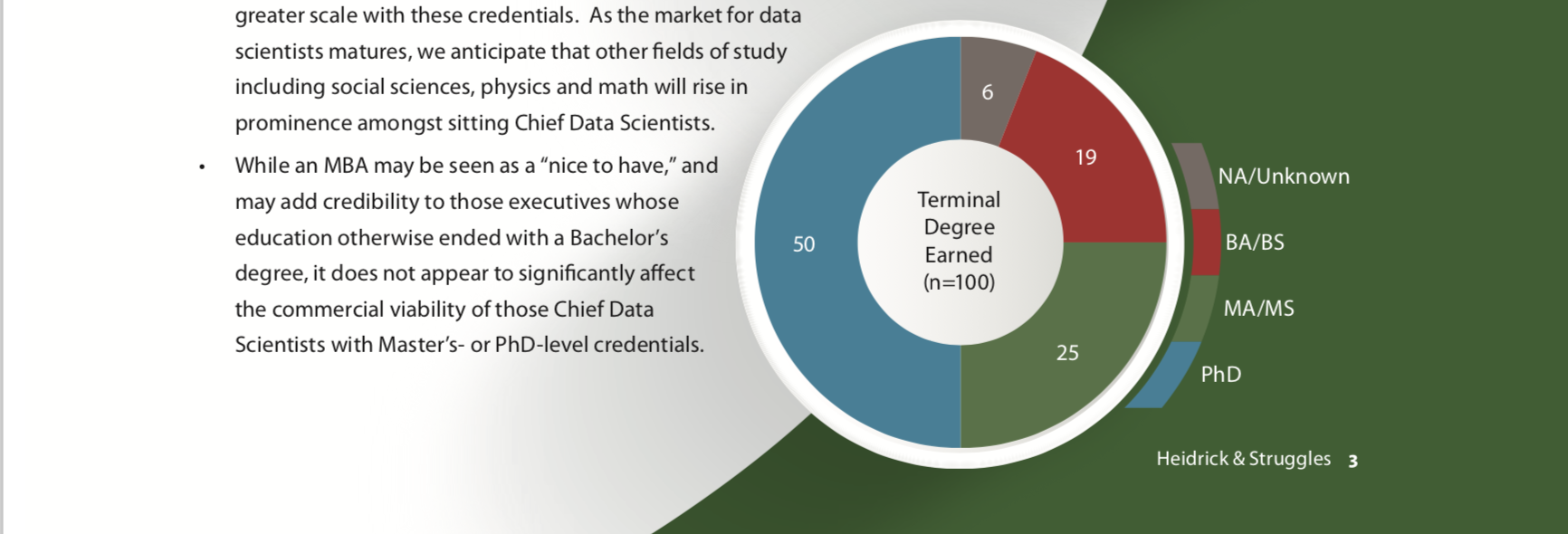
Sure, this graph will not get the “best dataviz” award, but at least I understand what I’m looking at. My hope was too early. The next graph was as nonsense as the first three ones.
Finally, the report authors decided that it wasn’t enough to draw smartly looking color segments enclosed in a circle. They decided to add some cool looking lines. The authors remained faithful to their decision to not let any meaning into their graphical aids
.
Can’t we treat these graphs as illustrations?
Before co-founding the life-changing StackOverflow, Joel Spolsky was, among other things, an avid blogger. His blog, JoelOnSoftware, was the first blog I started following. Joel writes mostly about the programming business and. In order not to intimidate the readers with endless text blocks, Joel tends to break the text with illustrations. In many posts, Joel uses pictures of a cute Husky as an illustration. Since JoelOnSoftware isn’t a cynology blog, nobody gets confused by the sudden appearance of a Husky. Which is exactly what an illustration is - a graphical relief that doesn’t disturb. But what would happen if Joel decided to include a meaningless class diagram? Sure a class diagram may impress the readers. The readers will also want to understand it and its connection to the text. Once they fail, they will feel angry, and rightfully so
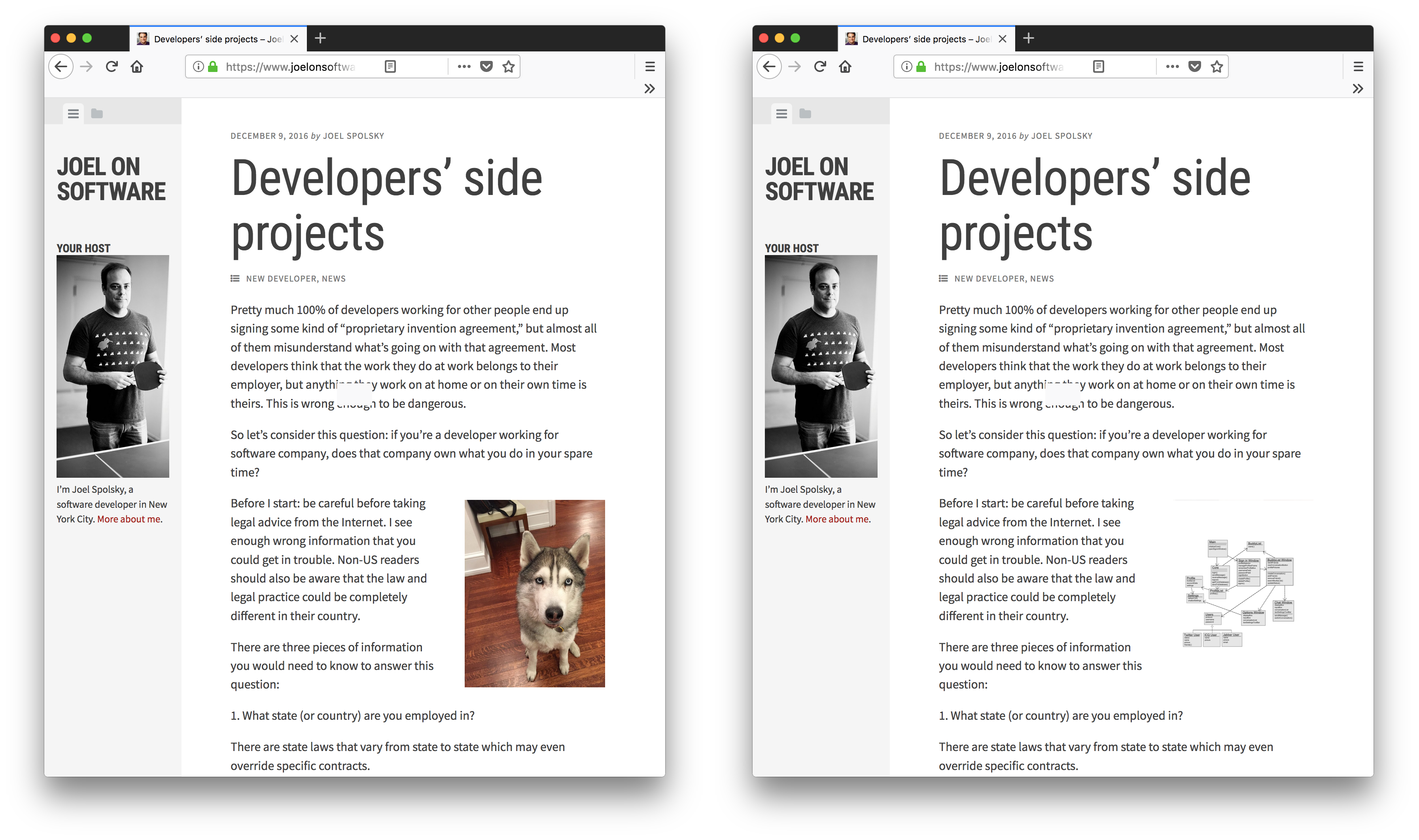
The bottom line
The bottom line is that people have to respect the rules of the domain they are writing about. If they don’t, their opinion cannot be trusted. That is why you should not take any pieces of advice related to data (or science) from H&S. Don’t get me wrong. It’s OK not to know the “grammar” of all the possible business domains. I, for example, know nothing about photography or dancing; my English is far from being perfect. That is why, I don’t write about photography, dancing or creative writing. I write about data science and visualization. It doesn’t mean I know everything about these fields. However, I did study a lot before I decided I could write something without ridiculing myself. So should everyone.