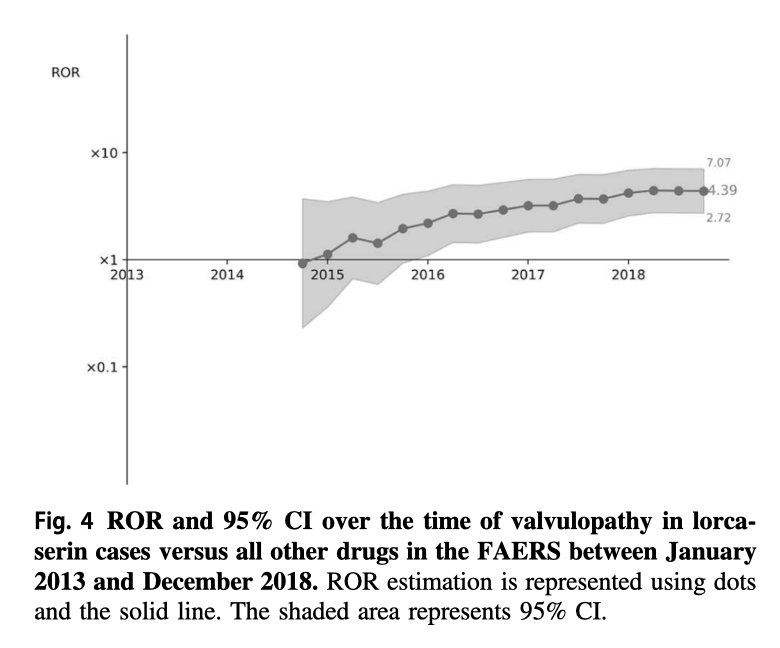
Would you buy a grammar book with a clear spelling mistake on its cover? I hope not. That’s what happened to IBM when it published it’s new data visualization guide. I didn’t bother reading the manual because of what IBM decided to use as the first image of their guide.

We use graphs to transfer information into images that are supposed to be later transformed in our brains to information. What visual attributes do we use to interpret the information behind a pie chart? It is the segment angle, its area, or maybe the arc length? Most probably, the answer is “all of the above” (see Robert Kosara’s works for more info). When done right, the three attributes of pie segments are linearly connected one to another, which allows synergism between the visual clues.
But what did our friends at IBM do? The deliberately distorted the data! I took the screenshot from the guide homepage and made some measurements.
The purple segment has the angle of 182 degrees, and the angle of the black segment is 75 degrees, which gives us the ratio of 2.42. However, while the radius of the purple segment is 135 pixels, the radius of the black one is only 110 pixels. Why is this a problem? Well, due to the radius differences, the ratio between the arc lengths is 2.91, and the ratio between the areas is 3.66. So now, let me ask you: what is the ratio between the numbers represented by the purple and the black segments?
It is correct that the colors that IBM people used in their guide are neat, but data visualization that distorts information is not visualization but a piece of garbage. I assume that IBM produces decent computers, but don’t learn data visualization from them

















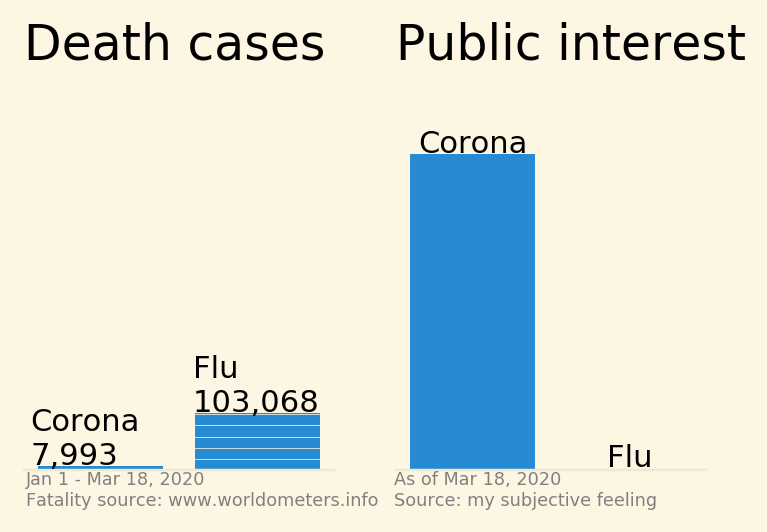

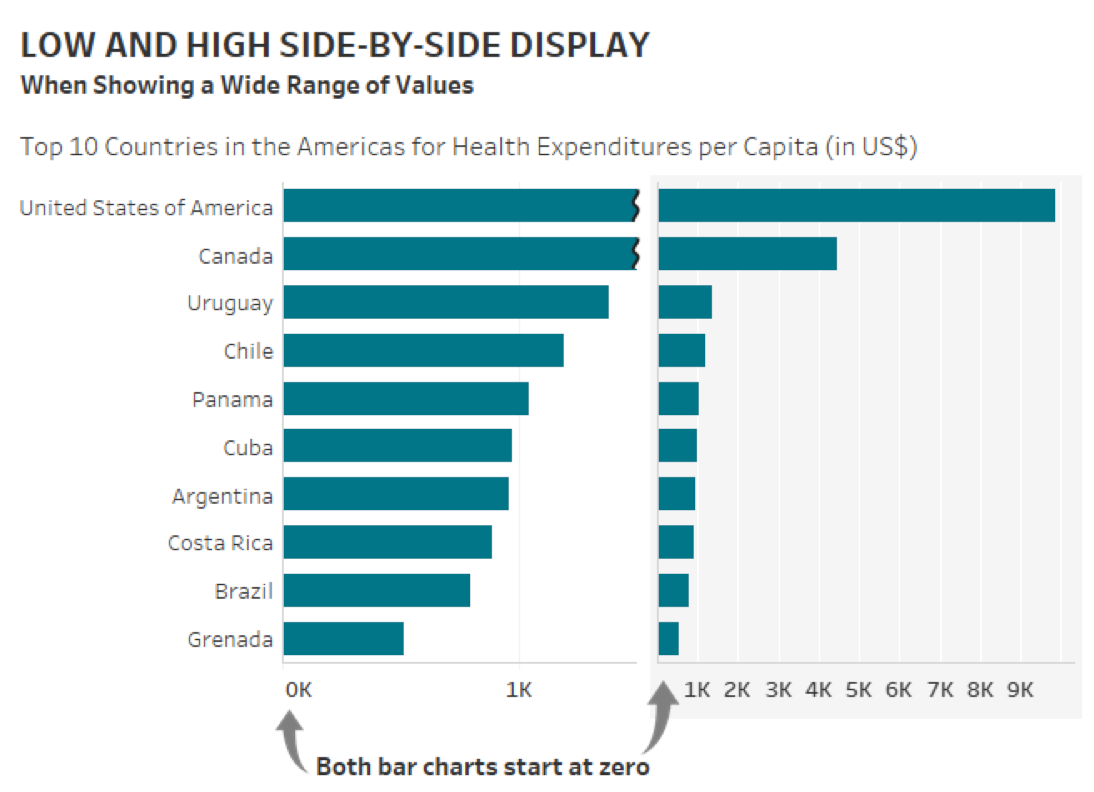
 Taken from
Taken from  Taken from
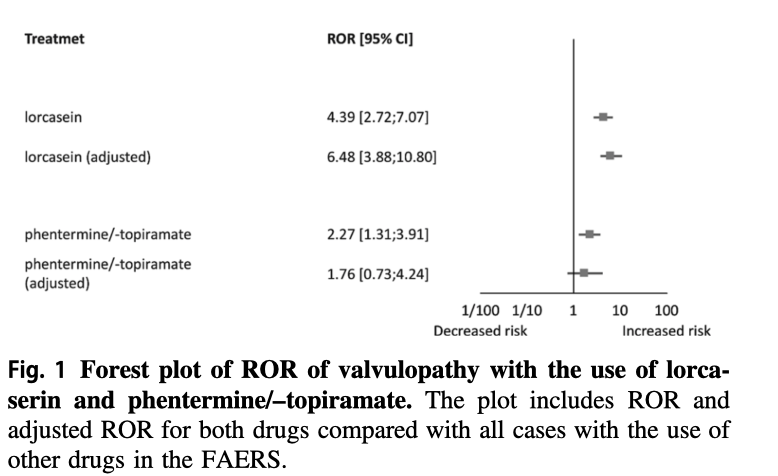
Taken from