“Climbing Invisible Ladders and Falling into Deep Holes: A Discourse in Five Parts” is a witty, engaging, and profoundly insightful exploration of corporate dynamics and career progression.”

Climbing Invisible Ladders and Falling Deep Holes: A Discourse in Five Parts
DRAMATIS PERSONAE
BORIS: A seasoned data scientist, middle-aged but ridiculously good-looking. An ex-Soviet Israeli, he adds an extra layer of cynicism to his character, complemented by a mysterious Russian-Israeli accent.
LAURA: The epitome of kindness, Laura is an American HR manager, and potentially the nicest person you’ll ever meet. She wears a constant, sincere smile.
DAPHNE: As a junior software developer, Daphne is smart and ambitious, constantly seeking opportunities to grow and evolve in her career.
Part 0. Prologue
FADE IN:
INT. HOTEL BAR - NIGHT
BORIS, LAURA, and DAPHNE sit around a table, each wearing a company name tag. A thought bubble appears above BORIS, reading, “It’s bullshit.” Boris shakes his head, dispelling the bubble.
LAURA
(Thoughtfully)
I hear you, Daphne. It’s great that you’re considering a promotion just three months into your first job. However, you should understand that management is more of a lateral move rather than a vertical one.
BORIS
(Shakes head, dispelling the “bullshit” thought bubble again, speaks sternly)
Laura, I strongly disagree.
A thought bubble appears above LAURA, reading, “Not him again.”
LAURA
(Smiling)
Interesting, Boris. Why do you think so?
BORIS
(Sighs)
Let’s discuss the term “promotion.” What do we seek when we aim for a promotion? More money, more autonomy, and a higher social status, wouldn’t you agree?
LAURA
(Nods)
Absolutely! And that’s exactly why transitioning to leadership roles doesn’t necessarily mean more money. We compensate employees based on their impact, not their position in the organizational chart. We also value and celebrate developers as much, if not more than managers, so their social status is already at its peak. All that managers do is facilitate developers in performing their jobs.
Part 1. Social status
BORIS
Here’s where I beg to differ. Even the terminology we employ suggests a higher social status. I have a “manager,” a “team leader,” or even a “boss.” Regardless of how much you’d like me to believe that a manager’s role is to assist me, they’re still referred to as a manager, not an assistant. Moreover, my manager has a direct influence on my evaluation, an influence I don’t hold over them.
LAURA
(Amused)
Boris, you couldn’t be more mistaken! Have you forgotten the annual engagement survey that you complete each year? We specifically ask for your thoughts on your team lead.
BORIS
Yes, but you ask both me and all my teammates, so my individual voice is diluted. Moreover, my team leader’s superior —
(Cynically, with air quotes)
“l e a d e r,” not assistant —
(Continues)
provides their direct feedback.
(Sips from a glass of cheap gin, longing for it to be Arak)
And that’s just one aspect. Our vacation policy is indeed generous, but it explicitly states that I need my team lead’s approval before taking time off. My team lead doesn’t require my consent for their time off; they consult their own superior. So yes, a manager does hold a higher social status than an individual contributor.
Part 2. Autonomy
LAURA
You know what? I’ll give you that. But when it comes to professional autonomy, an experienced individual contributor has the full power to decide how they solve the problem they work on.
(Daphne smiles)
BORIS
(takes another sip from the gin glass)
Oh, this is not true either. Take me as an example. I’m not a manager. It is true that I have the autonomy to decide how to solve a problem, but I often don’t get to decide what problem to solve. I can have some influence on this matter, but when my opinion collides with the opinion of my manager or their managers, my opinion is put aside.
DAPHNE
(interrupts)
Right, the other day…
LAURA
(irritated)
You can always take initiative and start working on something that really interests you.
(adds pathos to her voice)
In our company, you can write your own history. Identify a problem, start working on a solution in your spare time, and one day you may convince the management that the solution is worth adopting and expanding.
DAPHNE
(sarcastically)
Free time? You must be kidding.
BORIS
For once, I agree with Laura. We have some free time, and moderate switching between projects might be a good form of rest. Not only that, but a technical hands-on person might also have more tools to solve a technical problem. But… a manager usually has better knowledge of company needs and, more importantly, company politics. That is why a manager’s pet project has a higher chance of being accepted by the company than the one initiated by an IC.
LAURA
(doubtful)
Hmm… I don’t know… Well, at least in terms of money, management isn’t promotion.
Part 3. Money
BORIS
(Chuckles)
Ah, money. Who doesn’t love money? However, I’m afraid I must disagree with you on this one.
LAURA
(Joyfully)
Well, as the head of HR, not you, I understand how compensation is calculated. You are all compensated based on your impact on our business, nothing more. I know several managers who earn less than the individuals they manage.
(Makes a dramatic pause)
It’s all about the impact!
BORIS
(Points a finger)
Correct. I presume that when you talk about these managers, you’re primarily referring to team leads. Am I right?
LAURA
(Pauses, then nods)
Actually, yes.
BORIS
(Chuckles)
You see, a team lead may earn less than a developer, researcher, or designer they manage, especially if they oversee senior and experienced professionals. But who can bring a greater impact to the business: a senior programmer or a senior manager?
DAPHNE
(Looks puzzled)
What do you mean?
BORIS
(Turns to Daphne)
Let’s take me as an example. I’m an outstanding data scientist, one of the best in the field.
(LAURA and DAPHNE nod in agreement)
Nevertheless, my brain operates optimally only 8-9 hours a day. On the other hand, David, the head of the Modelling division, is also a top-tier professional, and he too works 8-9 hours a day. But since he is at the helm of a division, his work is amplified by the ten people who work under him.
LAURA
There are thirteen now; we’ve hired two additional scientists.
BORIS
(Turns to Daphne)
See what I mean? David’s impact is over a dozen times larger than mine. Therefore, it would only make sense for his salary to exceed mine.
Everyone falls silent. Boris signals for a refill. Daphne appears dejected.
Part 4. Don’t lose your sleep over this
BORIS
(Looks at Daphne)
Don’t lose sleep over this.
Boris takes a salt shaker, opens it, pours the salt onto the table, and draws two partially overlapping bell curves.
BORIS
Here’s an analogy. Consider men and women. On average, men are stronger than women, right?
Laura and Daphne nod their heads. Laura looks concerned, anticipating that Boris might say something stupidly inappropriate.
BORIS
(Points to the salt)
In this graph, the X-axis represents strength, and the two curves represent men and women. Now, what does this mean? Does it mean that all men are stronger than all women? Certainly not! There are many strong women and many weak men! You can see this by looking at the overlapping part of these curves here.
He points to the intersecting area of the two curves drawn in the salt.
BORIS
(Continues)
Now, let’s return to our original discussion. Let’s say that the X-axis now stands for “promotion” – a vague amalgamation of social status, power, and money. I hope I’ve convinced you that management is a form of promotion, but consider these curves. As in the men versus women case, there will be many individual contributors positioned higher on the promotion axis than some managers.
Laura looks relieved. Daphne is deep in thought.
DAPHNE
That makes sense. I could focus on improving my development skills… Conversely, I could invest the same energy into enhancing my management skills and transition to the better curve.
The atmosphere in the room becomes dense with contemplation.
Part 5. You have to like your job
BORIS
(pensively)
You’re right but also somewhat wrong. Becoming good at your work is hard. It becomes even harder if you don’t enjoy it. If you like managing people, go for it. Enjoy the process, grow your skills, and plan the mansion you want to buy when you’re a big-shot CEO.
He takes a sip of his drink.
BORIS
(continuing)
But if you enjoy writing good code more than dealing with people, you might become miserable during your quest for a management career. Being miserable won’t leave enough energy to improve your skills, and you might end up as a mediocre, bitter, mid-level manager who’s jealous of her younger self.
Laura smiles in agreement.
BORIS
(sincerely)
I fully agree with that. In the past, in some companies, such a move would be perceived as a demotion, but now and not here. Nowadays, many companies, small and big, recognize that management is a separate profession. The atmosphere in our company is kind enough to accept that people need to search for their path in life. Take me for example I “stepped down” from a management position twice. I don’t regret taking those positions. Neither do I regret stepping down from them.
Daphne looks thoughtful, contemplating the information she’s received.
DAPHNE
(tentatively)
I think I need to explore more about myself. I need to see what suits me best. But I guess I won’t know until I try.
Laura and Boris share a look of approval.
Boris raises his glass for a toast.
BORIS
(smiling)
To exploration and finding what truly makes us happy!
Everyone raises their glasses, and the scene ends on a positive note of camaraderie and mutual respect.
FADE OUT.
FADE IN.
INT. HOTEL BAR TABLE – NIGHT
The conversation has come to a natural end. Boris stays at the table. Daphne and Laura are leaving the bar, their faces illuminated by the soft lights of the lobby.
LAURA
(sincerely)
Remember, Daphne. You have a whole community here that believes in you. Reach out anytime.
(checks to make sure nobody’s listening)
And remember, don’t take Boris too seriously. He’s… well… he’s Boris.
FADE OUT.
THE END

























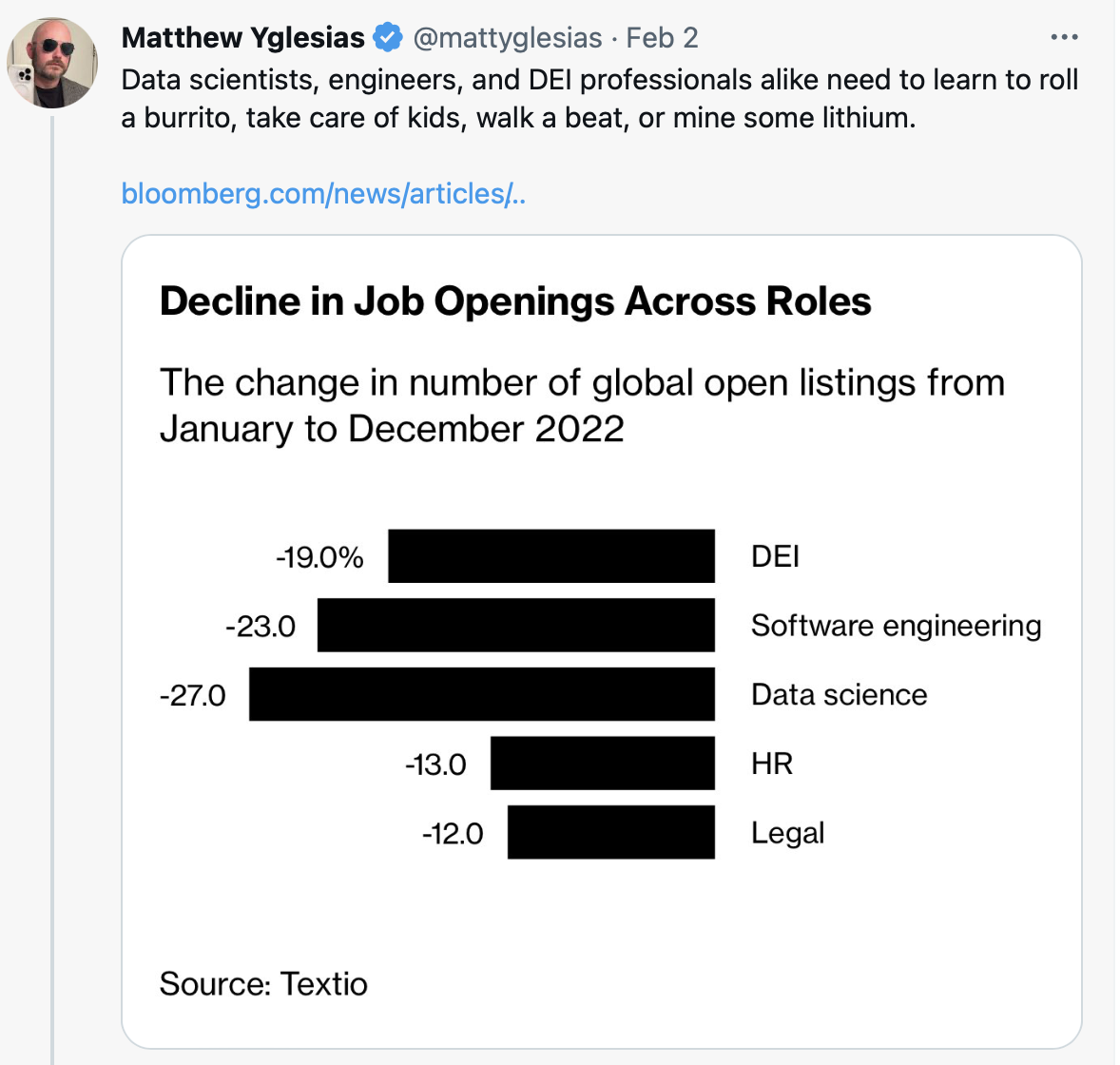









{kind=link}